SemanticAudio
Audio Generation and Editing in Semantic Space
Abstract
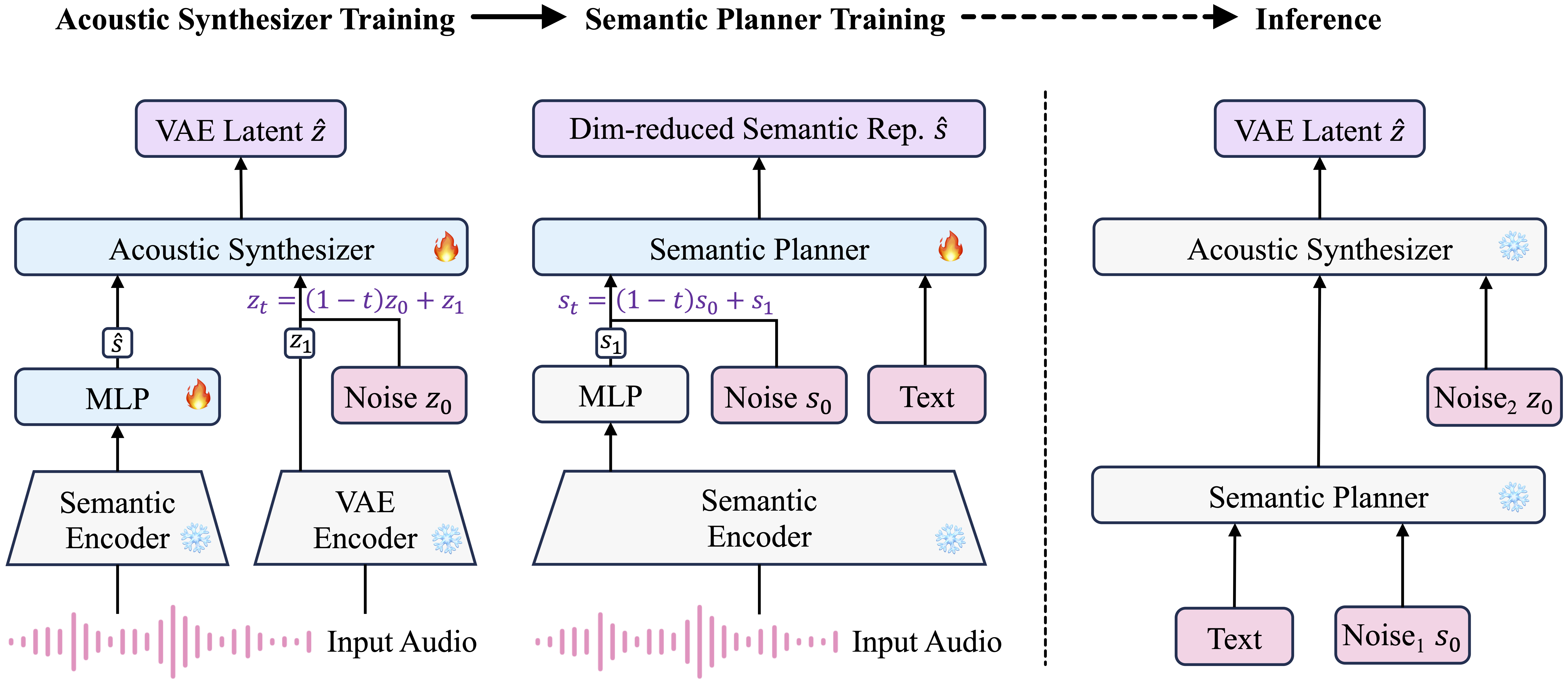
In recent years, Text-to-Audio Generation has achieved remarkable progress, offering sound creators powerful tools to transform textual inspirations into vivid audio. However, existing models predominantly operate directly in the acoustic latent space of a Variational Autoencoder (VAE), often leading to suboptimal alignment between generated audio and textual descriptions. In this paper, we introduce SemanticAudio, a novel framework that conducts both audio generation and editing directly in a high-level semantic space. We define this semantic space as a compact representation capturing the global identity and temporal sequence of sound events, distinct from fine-grained acoustic details. SemanticAudio employs a two-stage Flow Matching architecture: the Semantic Planner first generates these compact semantic features to sketch the global semantic layout, and the Acoustic Synthesizer subsequently produces high-fidelity acoustic latents conditioned on this semantic plan. Leveraging this decoupled design, we further introduce a training-free text-guided editing mechanism that enables precise attribute-level modifications on general audio without retraining. Specifically, this is achieved by steering the semantic generation trajectory via the difference of velocity fields derived from source and target text prompts. Extensive experiments demonstrate that SemanticAudio surpasses existing mainstream approaches in both semantic alignment and audio fidelity.
Audio Generation Demos
Below are audio samples comparing our SemanticAudio with the Base Model, AudioLDM, and Ground Truth recordings. Samples are ordered by caption length from shortest to longest.
Audio Generation Framework
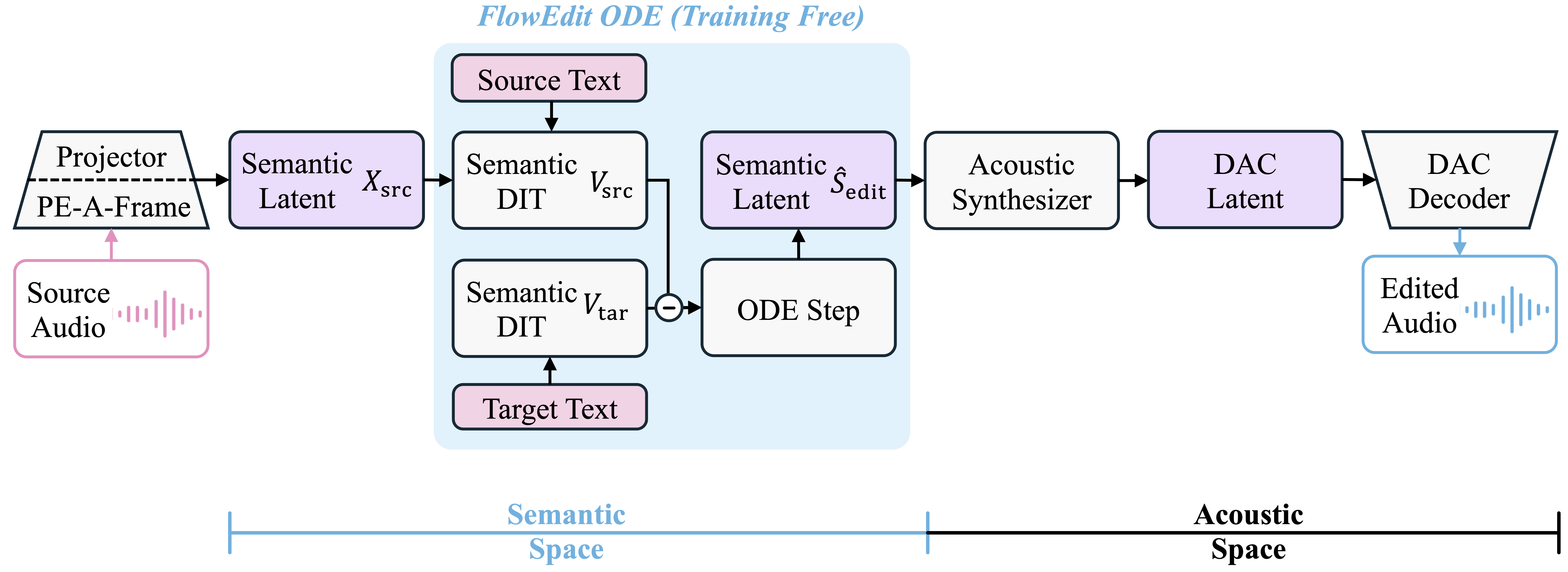
Audio Edit Demos
Below are audio editing samples demonstrating our training-free text-guided editing mechanism. We show the source audio with its original caption, the target caption for editing, and results from two editing modes: with source caption guidance and without source caption guidance.
Audio Editing Framework